
原文 CHE_NG程 CHE_NG程 2020-11-05
大数据技术原理与应用
本文是对《大数据与云计算导论》课程知识点的应试总结。基本涵盖了《大数据技术原理与应用》的重点内容。
第一章 大数据概述
1、三次信息化浪潮
| 信息化浪潮 | 发生时间 | 标志 | 解决的问题 | 代表企业 |
|---|---|---|---|---|
| 第一次浪潮 | 1980年前后 | 个人计算机 | 信息处理 | Intel、AMD、IBM |
| 第二次浪潮 | 1995年前后 | 互联网 | 信息传输 | 雅虎、谷歌、阿里巴巴 |
| 第三次浪潮 | 2010年前后 | 物联网、云计算和大数据 | 信息爆炸 | 亚马逊、谷歌、阿里云 |
注:信息化浪潮每15年一次。
2、信息科技为大数据时代提供技术支持
- 存储设备容量不断增加存储单位:bit、Byte、KB、MB、GB、TB、PB、EB(ZB、YB、BB、NB、DB)
- CPU处理能力大幅提升
- 网络带宽不断增加
3、大数据的特点(5个)
- 数据量大(Volume)
- 数据类型繁多(Variety)
- 处理速度快(Velocity)
- 价值密度低(Value)
- 真实性(Veracity)
4、大数据的影响
1、大数据对科学研究的影响
人类自古以来在科学研究上先后经历了实验、理论、计算和数据四种范式:
- 第一种范式:实验科学
- 第二种范式:理论科学
- 第三种范式:计算科学
- 第四种范式:数据密集型科学
2、大数据对思维方式的影响
- 全样而非抽样
- 效率而非精确
- 相关而非因果
5、大数据关键技术
- 数据采集与预处理
- 数据存储和管理
- 数据处理与分析
- 数据安全和隐私保护
6、大数据计算模式
| 大数据计算模式 | 解决问题 | 代表产品 |
|---|---|---|
| 批处理计算 | 针对大规模数据的批量处理 | MapReduce、Spark等 |
| 流计算 | 针对流数据的实时计算 | Strom、Stream、银河流数据处理平台等 |
| 图计算 | 针对大规模图结构数据的处理 | Pregel、GraphX、PowerGraph等 |
| 查询分析计算 | 大规模数据的存储管理和查询分析 | Dremel、Hive等 |
7、云计算
1、概念
通过网络提供可伸缩的、廉价的分布式计算能力
2、云计算的关键技术
- 虚拟化:云计算基础架构的基石
- 分布式存储
- 分布式计算
- 多租户
8、物联网
1、概念
物物相连的互联网
从技术架构上来看,物联网可分为四层:感知层、网络层、处理层和应用层
2、物联网关键技术
- 识别和感知技术(二维码、RFID、传感器等)
- 网络与通信技术
- 数据挖掘与融合技术
9、大数据与云计算、物联网的关系
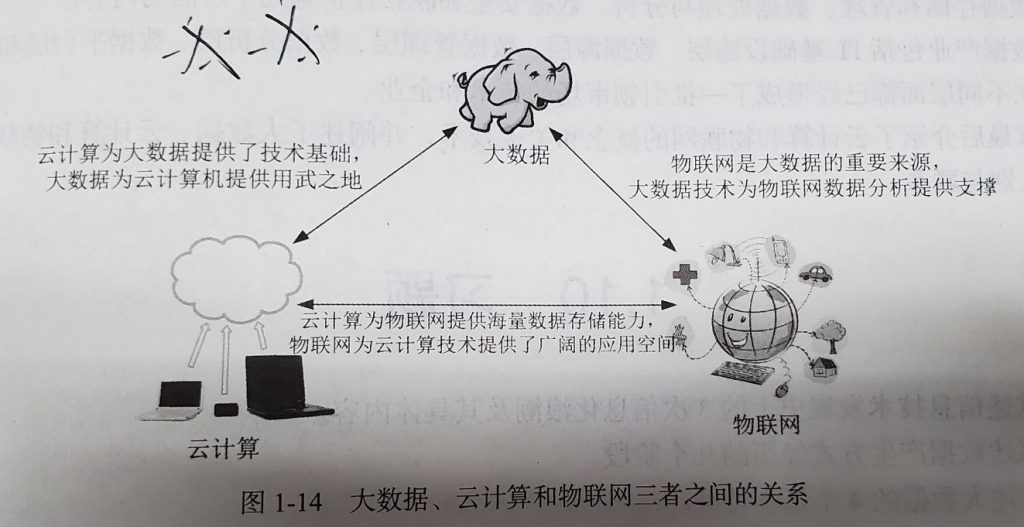
- 区别:大数据侧重于海量数据的存储、处理与分析,从海量数据中发现价值,服务于生产和生活;云计算本质上旨在整合和优化各种IT资源,并通过网络以服务的方式廉价地提供给用户;物联网的发展目标是实现物物相连,应用创新是物联网发展的核心。
- 联系:大数据、云计算和物联网三者相辅相成。大数据根植于云计算,大数据分析的很多技术都来自于云计算,云计算的分布式数据存储和管理系统提供了海量数据的存储和管理能力,分布式并行处理框架MapReduce提供了海量数据的分析能力;大数据为云计算提供了“用武之地”;物联网的传感器源源不断产生的大量数据,构成了大数据的重要来源,同时物联网需要借助于云计算和大数据技术,实现物联网大数据的存储、分析和处理。
第二章 大数据处理框架Hadoop
1、Hadoop简介
Hadoop是一个开源分布式计算平台
Hadoop的核心包括:HDFS(前身:NDFS)和MapReduce。
2、Hadoop的特性
- 高可靠性
- 高效性
- 高扩展性
- 高容错性
- 成本低
- 运行在Linux平台上
- 支持多种编程语言
第三章 分布式文件系统HDFS
1、HDFS含义
Hadoop分布式文件系统,是GFS的开源实现
2、DFS含义
分布式文件系统(DFS)是一种通过网络实现文件在多台主机上进行分布式存储的文件系统
3、分布式文件系统的结构
- 主节点(Master Node):名称节点(NameNode)
- 从节点(Slave Node):数据节点(DataNode)
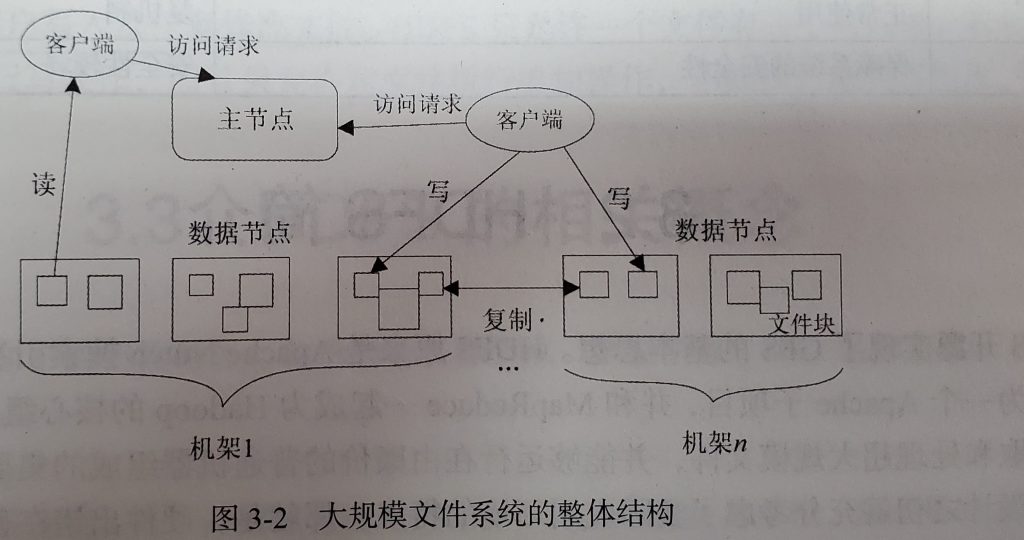
4、分布式文件系统的设计需求
分布式文件系统的设计目标主要包括:透明性、并发控制、可伸缩性、容错以及安全需求等。
5、HDFS特性
1、目标
- 兼容廉价的硬件设备
- 流数据读写
- 大数据集
- 简单的文件模型
- 强大的跨平台兼容性
2、局限性
- 不适合低延迟数据访问
- 无法高效存储大量小文件
- 不支持多用户写入及任意修改文件
6、HDFS相关概念
1、块
以数据块为单位进行存储(1.0默认64MB)
**目的:**最小化寻址开销
好处:
- 支持大规模文件存储
- 简化系统设计
- 适合数据备份
2、名称节点和数据节点
名称节点的核心数据结构:FsImage和EditLog。
| NameNode | DataNode |
|---|---|
| 存储元数据 | 存储文件内容 |
| 元数据存在内存中 | 文件内容保存在磁盘中 |
| 保存文件Block于DataNode间的映射关系 | 维护Block与DataNode本地文件的映射关系 |
3、第二名称节点
作用:
- Edit log与FsImage的合并操作
- 作为名称节点的“检查点”(冷备份)
7、HDFS体系结构
1、HDFS命名空间管理
HDFS的命名空间包含目录、文件和块。
HDFS集群中只有一个命名空间,并且只有唯一一个名称节点。
2、通信协议
- 构建在TCP/IP协议基础之上
- 使用客户端协议与名称节点进行交互
- 名称节点和数据节点之间使用数据节点协议进行交互
- 客户端与数据节点的交互通过RPC实现
3、局限性
- 命名空间的限制
- 性能的瓶颈
- 隔离问题
- 集群的可用性
8、HDFS的存储原理
数据的冗余存储、数据存取策略、数据错误与恢复
1、数据的冗余存储
优点:
- 加快数据传输速度
- 容易检查数据错误
- 保证数据的可靠性
2、数据存取策略
1、数据存放
冗余因子默认为3。
**内部请求:**第一个副本放置在写操作请求的数据节点上;
**外部请求:**挑一个不太忙的数据节点,第二个副本放置在不同于第一个副本的机架的数据节点上,第三个副本放置在第一个副本的机架的其他数据节点上。
2、数据读取
当发现某个数据块副本对应的机架ID与客户端对应的ID一样时,优先选择该副本,否则就随机。
3、数据复制
采用流水线复制的策略(4KB)
3、数据错误与恢复
9、HDFS常用命令
- hadoop fs -get
- hadoop fs -put
第四章 分布式数据库HBase
1、HBase含义
Hadoop DataBase(HBase)是针对谷歌BigTable的开源实现。
2、HBase与传统关系数据库的对比分析
| 关系数据库 | HBase | |
|---|---|---|
| 数据类型 | 具有丰富的数据类型和存储方式 | 未经解释的字符串 |
| 数据操作 | 丰富的操作 | 不存在复杂的表与表之间的关系 |
| 存储模式 | 基于行模式存储 | 基于列存储 |
| 数据索引 | 可以构建复杂的多个索引 | 只有一个索引——行键 |
| 数据维护 | 更新操作会用最新的当前值去替代旧值 | 生成一个新的版本,旧有版本依然保留 |
| 可伸缩性 | 很难实现横向扩展,纵向扩展空间有限 | 可实现灵活的水平扩展 |
3、HBase数据模型
1、相关概念
HBase是一个稀疏、多维、持久化存储的映射表,它采用行键、列族、列限定符和时间戳进行索引。
2、数据坐标
“四维坐标”:[行键,列族,列限定符,时间戳]
4、HBase实现原理
1、HBase的功能组件
- 库函数
- 一个Master主服务器
- 许多个Region服务器
2、Region的定位
Region标识符:“表名+开始主键、RegionID”
5、HBase运行机制
1、HBase系统架构
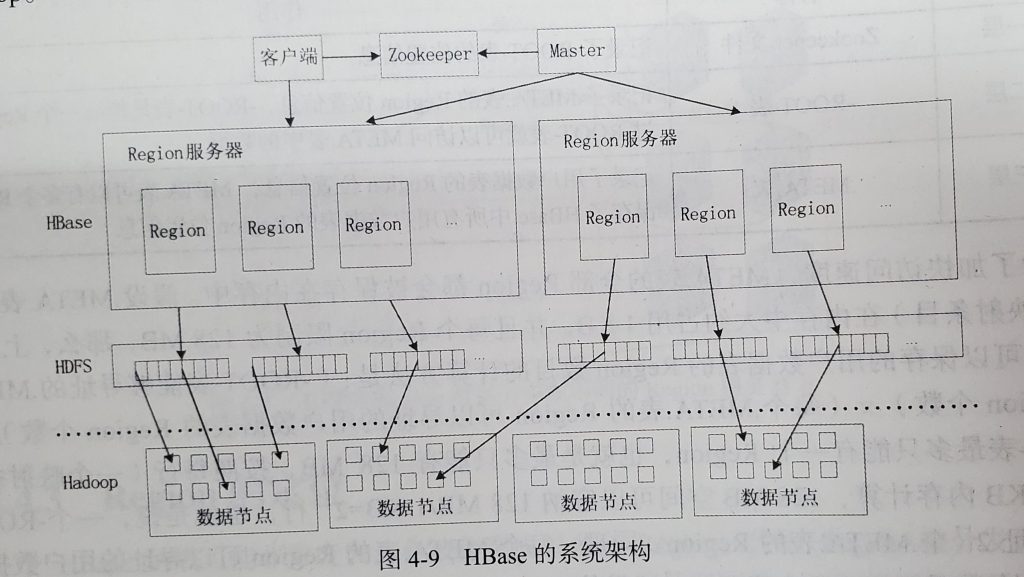
2、Region服务器的工作原理
每个Region对象又是由多个Store组成的,每个Store对应了表中的一个列族的存储。
每个Store又包含了一个MemStore和若干个StoreFile。
6、HBase常用Shell命令
- create:创建表
- list:列出HBase中所有的表信息
- put:向表、行、列指定的单元格添加数据
- get:通过指定表名、行、列、时间戳、时间范围和版本号来获得相应单元格的值
- scan:浏览表的相关信息
第五章 NoSQL数据库
1、NoSQL简介
1、含义
Not Only SQL
2、特点
- 灵活的可扩展性
- 灵活的数据模型
- 与云计算紧密融合
2、NoSQL的四大类型
| 类型 | 代表 |
|---|---|
| 键值数据库 | Redis、Memcached |
| 列族数据库 | Cassandra、HBase |
| 文档数据库 | MongoDB |
| 图数据库 | Neo4j |
3、NoSQL的三大基石
1、CAP
- C(Consistency):一致性
- A(Availability):可用性
- P(Tolerance of Network Partition):分区容忍性
CAP理论最多同时满足三个中的两个。
- CA。强调一致性(C)和可用性(A),放弃分区容忍性(P)。eg:传统的关系数据库(MySQL、SQL Server等)。
- CP。强调一致性(C)和分区容忍性(P),放弃可用性(A)。eg:Neo4j、BigTable和HBase等。
- AP。强调可用性(A)和分区容忍性(P),放弃一致性(C)。eg:Cassandra、Dynamo等。
2、BASE
BASE
- BA(Basically Available):基本可用
- S(Soft-state):软状态
- E(Eventual consistency):最终一致性
ACID:一个数据库事务具有ACID四性
- A(Atomicity):原子性
- C(Consistency):一致性
- I(Isolation):隔离性
- D(Durability):持久性
4、三个数据库阵营
- OldSQL(传统关系数据库)
- NoSQL
- NewSQL
第六章 云数据库
1、云数据库概念
云数据库是部署和虚拟化在云计算环境中的数据库。
2、云数据库的特性
- 动态可扩展
- 高可用性
- 较低的使用代价
- 易用性
- 高性能
- 免维护
- 安全
第七章 MapReduce
1、MapReduce简介
MapReduce是一种分布式并行编程框架,以Map和Reduce为核心函数。
MapReduce的设计理念:计算向数据靠拢。
Map函数和Reduce函数都以<key,value>作为输入。
2、MapReduce的工作流程
第八章 Hadoop再探讨
1、针对Hadoop的改进与提升
| 组件 | 1.0的问题 | 2.0的改进 |
|---|---|---|
| HDFS | 单一名称节点,存在单点失效问题 | 设计了HDFS HA,提供名称节点热备份机制 |
| HDFS | 第一命名空间,无法实现资源隔离 | 设计了HDFS联邦,管理多个命名空间 |
| MapReduce | 资源管理效率低 | 设计理新的资源管理框架YARN |
2、HDFS 2.0的新特性
1、HDFS HA
2、HDFS联邦
优势:
- HDFS集群可扩展性
- 性能更高效
- 良好的隔离性
3、新一代资源管理调度框架YARN
1、YARN体系结构
YARN体系结构包含了三个组件:
- ResourceManager
- ApplicationMaster
- NodeManager
2、YARN的发展目标
YARN的目标就是实现“一个集群多个框架”,即在一个集群上部署一个统一的资源调度管理框架YARN,在YARN之上可以部署其他各种计算框架。
3、Hadoop生态系统中具有代表性的功能组件
1、Pig
提供了类似SQL的Pig Latin语言。
Pig会自动把用户编写的脚本转换成MapReduce作业在Hadoop集群上运行。
2、Tez
Tez是Apache开源的支持DAG作业的计算框架。
核心思想:将Map和Reduce两个操作进一步拆分。
3、Kafka
一种分布式发表订阅消息系统。
满足在线实时处理和批量离线处理。
第九章 Spark
1、Spark简介
Spark是基于内存计算的大数据并行计算框架。
特点:
- 运行速度快
- 容易使用
- 通用性
- 运行模式多样
2、Scala简介
Scala是一门多范式编程语言,面向函数编程。
3、Spark运行架构
1、基本概念
- RDD:弹性分布式数据集
- DAG:有向无环图
2、RDD
**概念:**分布式对象集合。
依赖关系:
- 窄依赖:一个父RDD的分区对应于一个子RDD的分区,或多个父RDD的分区对应于一个子RDD的分区;
- 宽依赖:存在一个父RDD的一个分区对应于一个子RDD的多个分区。
第十章 流计算
1、流计算概述
1、流计算概念
流计算即针对流数据的实时计算。
2、批量处理和实时处理
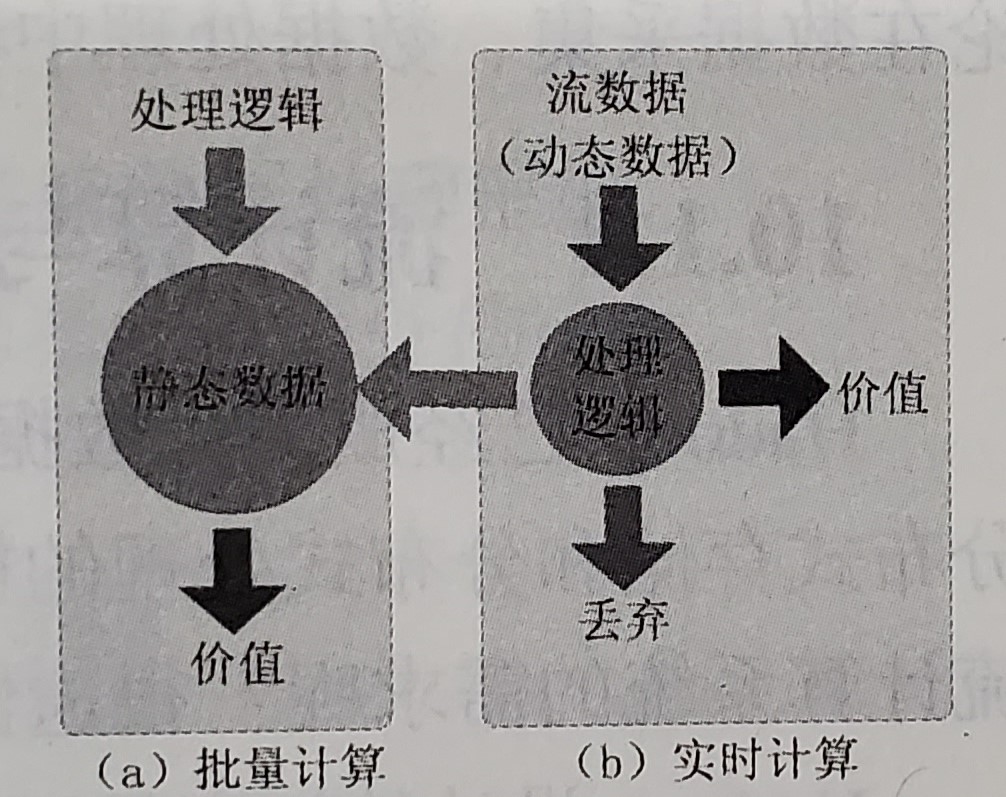
2、流计算的处理流程
- 数据实时采集
- 数据实时计算
- 实时查询服务
3、开源流计算框架Storm
Storm的设计思想:
- Streams流数据(Streams)是一个无限的Tuple序列。
- SpoutsSpouts是Stream的源头,会从外部读取流数据并持续发出Tuple。
- BoltsBolts既可以处理Tuple,也可以将处理后的Tuple作为新的Streams发给其他Bolts。
- TopologySpouts和Bolts组成的网络。
- Stream Groupings用于告知Topology如何在两个组件间进行Tuple的传送。
4、Spark Streaming
Spark Streaming与Storm的对比
Spark Streaming无法实现毫秒级的流计算,而Storm则可以实现毫秒级响应。
第十一章 图计算
1、图计算概述
**含义:**对图结构的计算。
**BSP模型:**整体同步并行计算模型,又名“大同步模型”。
一次BSP计算过程包括一系列全局超步(超步就是指计算中的一次迭代),每个超步包括3个组件:
- 局部计算
- 通信
- 栅栏同步
2、Pregel简介
Pregel是一种基于BSP模型实现的并行图处理系统。
展开阅读全文
上一篇: 学习十四五规划和2035年远景目标建议
下一篇:华山

 扫码打开小程序可评论文章保存图片,在“我的”有实时在线客服哦,
扫码打开小程序可评论文章保存图片,在“我的”有实时在线客服哦,
 关注我的公众号为您分享各类有用信息
关注我的公众号为您分享各类有用信息 分享录多端跨平台系统
分享录多端跨平台系统 粤公网安备 44011202001306号
粤公网安备 44011202001306号